Hãy tưởng tượng bạn có một cuốn sách dày 1000 trang. Giả sử bạn đang cố gắng tìm trang chứa thông tin liên quan đến một từ cụ thể nào đó. Nếu không có trang mục lục, bạn sẽ phải lật từng trang một, quá trình này có thể mất hàng giờ, thậm chí hàng ngày. Nhưng với trang mục lục, bạn biết chính xác cần tìm ở đâu! Một khi đã tìm thấy mục lục phù hợp, bạn có thể nhanh chóng nhảy đến trang đó. Mục lục, vì được sắp xếp theo thứ tự bảng chữ cái và cung cấp số trang cho từng thông tin cụ thể, giúp chúng ta tiết kiệm rất nhiều thời gian lật giở từng trang sách.

Database indexes hoạt động theo cách tương tự. Chúng dẫn đường cho cơ sở dữ liệu đến đúng vị trí của dữ liệu, giúp việc truy xuất dữ liệu nhanh hơn và hiệu quả hơn.
Trong bài viết này, chúng ta sẽ cùng khám phá:
- Database indexes là gì?
- Chúng hoạt động như thế nào?
- Lợi ích của việc sử dụng chúng.
- Các loại indexes khác nhau.
- Chúng sử dụng cấu trúc dữ liệu nào?
- Cách sử dụng chúng một cách thông minh?
1. Database Indexes Là Gì?
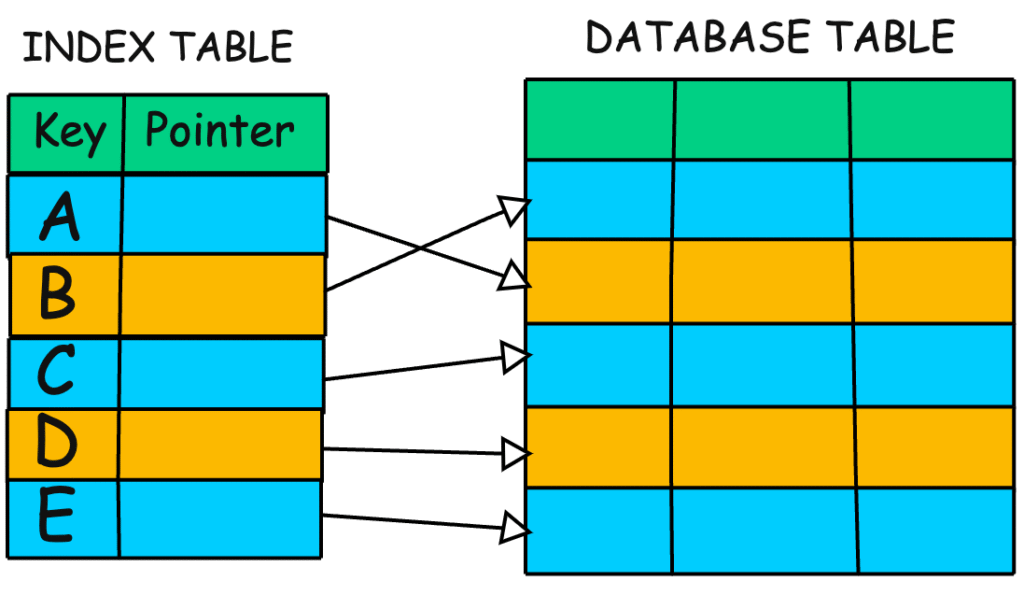
Một database index là một bảng tra cứu siêu hiệu quả, cho phép cơ sở dữ liệu tìm kiếm dữ liệu nhanh hơn rất nhiều. Nó lưu trữ các giá trị của cột được index cùng với các con trỏ (pointers) đến các hàng (rows) tương ứng trong bảng. Nếu không có index, cơ sở dữ liệu có thể phải quét (scan) từng hàng đơn lẻ trong một bảng khổng lồ để tìm thứ bạn muốn – một quá trình chậm chạp và đau đầu. Tuy nhiên, với index, cơ sở dữ liệu có thể xác định chính xác vị trí của dữ liệu mong muốn thông qua các con trỏ trong index.
Cách tạo Indexes?
Dưới đây là một ví dụ về việc tạo index trong cơ sở dữ liệu MySQL. Giả sử chúng ta có một bảng tên là employees với cấu trúc như sau:
CREATE TABLE employees (
id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
department VARCHAR(50),
salary DECIMAL(10, 2)
);Bây giờ, hãy tạo một index trên cột last_name để cải thiện hiệu suất của các truy vấn thường xuyên tìm kiếm hoặc sắp xếp dựa trên họ.
CREATE INDEX idx_last_name ON employees (last_name);Trong ví dụ này, chúng ta sử dụng câu lệnh CREATE INDEX để tạo một index có tên là idx_last_name trên bảng employees. Index được tạo trên cột last_name.
Sau khi tạo index, các truy vấn liên quan đến điều kiện hoặc sắp xếp trên cột last_name sẽ được tối ưu hóa. Ví dụ:
SELECT * FROM employees WHERE last_name='Smith';Truy vấn này sẽ sử dụng index idx_last_name để nhanh chóng định vị các hàng có last_name là ‘Smith’, tránh được việc quét toàn bộ bảng (full table scan).
Bạn cũng có thể tạo indexes trên nhiều cột (composite indexes) nếu các truy vấn của bạn thường xuyên liên quan đến điều kiện trên nhiều cột cùng lúc. Ví dụ:
CREATE INDEX idx_name ON employees (first_name, last_name);Câu lệnh này tạo một composite index trên các cột first_name và last_name, rất hữu ích cho các truy vấn tìm kiếm hoặc sắp xếp dựa trên cả hai cột này.
2. Database Indexes Hoạt Động Như Thế Nào?
Dưới đây là giải thích từng bước về cách database indexes hoạt động:
- Index Creation (Tạo Index): Quản trị viên cơ sở dữ liệu tạo một index trên một cột hoặc tập hợp các cột cụ thể.
- Index Building (Xây dựng Index): Hệ thống quản lý cơ sở dữ liệu xây dựng index bằng cách quét bảng và lưu trữ các giá trị của cột được index cùng với một con trỏ đến dữ liệu tương ứng.
- Query Execution (Thực thi Truy vấn): Khi một truy vấn được thực thi, công cụ cơ sở dữ liệu sẽ kiểm tra xem có tồn tại index nào cho cột(s) được yêu cầu hay không.
- Index Search (Tìm kiếm Index): Nếu tồn tại index, cơ sở dữ liệu sẽ tìm kiếm trong index để lấy dữ liệu được yêu cầu, sử dụng các con trỏ để nhanh chóng định vị dữ liệu.
- Data Retrieval (Truy xuất Dữ liệu): Cơ sở dữ liệu truy xuất dữ liệu được yêu cầu, sử dụng các con trỏ từ index.
3. Lợi Ích Của Database Indexes
Database indexes mang lại nhiều lợi ích, bao gồm:
- Faster Query Performance (Hiệu suất truy vấn nhanh hơn): Indexes có thể cải thiện đáng kể hiệu suất truy vấn, đặc biệt đối với các bộ dữ liệu lớn, bằng cách giảm lượng dữ liệu cần quét.
- Reduced CPU Usage (Giảm sử dụng CPU): Bằng cách giảm số lượng hàng cần quét, indexes có thể làm giảm mức sử dụng CPU và tối ưu hóa việc sử dụng tài nguyên.
- Rapid Data Retrieval (Truy xuất dữ liệu nhanh chóng): Indexes cho phép truy xuất dữ liệu nhanh chóng cho các truy vấn liên quan đến điều kiện bằng nhau (equality) hoặc điều kiện phạm vi (range) trên các cột được index.
- Efficient Sorting (Sắp xếp hiệu quả): Indexes cũng có thể được sử dụng để sắp xếp dữ liệu một cách hiệu quả dựa trên các cột được index, loại bỏ nhu cầu thực hiện các thao tác sắp xếp tốn kém.
- Better Data Organization (Tổ chức dữ liệu tốt hơn): Indexes có thể giúp duy trì tổ chức và cấu trúc dữ liệu, giúp việc quản lý và bảo trì cơ sở dữ liệu dễ dàng hơn.
4. Các Loại Database Indexes
Indexes dựa trên Cấu trúc và Thuộc tính Khóa:
- Primary Index: Tự động được tạo khi một ràng buộc khóa chính (primary key constraint) được định nghĩa trên một bảng. Đảm bảo tính duy nhất và giúp tìm kiếm siêu nhanh bằng khóa chính.
- Clustered Index: Xác định thứ tự mà dữ liệu được lưu trữ vật lý trong bảng. Clustered index cực kỳ hữu ích khi chúng ta tìm kiếm trong một phạm vi. Chỉ có thể tồn tại một clustered index cho mỗi bảng.
- Non-clustered or Secondary Index: Index này không lưu trữ dữ liệu theo thứ tự của index. Thay vào đó, nó cung cấp một danh sách các con trỏ ảo hoặc tham chiếu đến vị trí nơi dữ liệu thực sự được lưu trữ.
Indexes dựa trên Phạm vi Dữ liệu:
- Dense index: Có một mục nhập cho mọi giá trị khóa tìm kiếm trong bảng. Phù hợp cho các tình huống dữ liệu có số lượng nhỏ các giá trị khóa tìm kiếm khác biệt hoặc khi cần truy cập nhanh đến các bản ghi riêng lẻ.
- Sparse index: Chỉ có mục nhập cho một số giá trị khóa tìm kiếm. Phù hợp cho các tình huống dữ liệu có số lượng lớn các giá trị khóa tìm kiếm khác biệt.
Các Loại Index Chuyên Biệt:
- Bitmap Index: Tuyệt vời cho các cột có cardinality thấp (ít giá trị khác biệt). Phổ biến trong kho dữ liệu (data warehousing).
- Hash Index: Một index sử dụng hàm băm (hash function) để ánh xạ các giá trị đến các vị trí cụ thể. Tuyệt vời cho các truy vấn khớp chính xác.
- Filtered Index: Index một tập con các hàng dựa trên một điều kiện lọc cụ thể. Hữu ích để cải thiện tốc độ truy vấn trên các cột thường xuyên được lọc.
- Covering Index: Bao gồm tất cả các cột mà một truy vấn yêu cầu ngay trong chính index, loại bỏ nhu cầu truy cập vào dữ liệu bảng cơ sở.
- Function-based index: Các index được tạo dựa trên kết quả của một hàm hoặc biểu thức được áp dụng cho một hoặc nhiều cột của bảng.
- Full-Text Index: Một index được thiết kế cho tìm kiếm toàn văn (full-text search), cho phép tìm kiếm dữ liệu văn bản một cách hiệu quả.
- Spatial Index: Được sử dụng để index các kiểu dữ liệu địa lý.
5. Indexes Sử Dụng Cấu Trúc Dữ Liệu Nào?
Các cấu trúc dữ liệu được sử dụng phổ biến nhất để hỗ trợ indexes là B-Trees, Hash Tables và Bitmaps.
B-Tree (Balanced Tree)
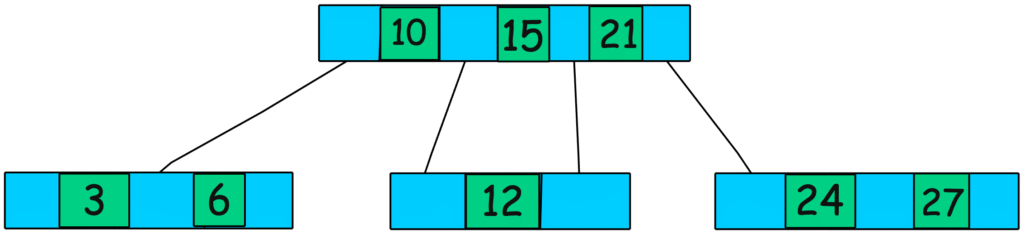
Hầu hết các công cụ cơ sở dữ liệu đều sử dụng B-Tree hoặc một biến thể của B-Tree như B+ Trees.
B-Trees có cấu trúc phân cấp với một nút gốc (root node), các nút nội (internal nodes – index nodes) và các nút lá (leaf nodes). Mỗi nút trong B-Tree chứa một mảng được sắp xếp các khóa (keys) và các con trỏ đến các nút con.
Dưới đây là lý do tại sao chúng lại phù hợp đến vậy:
- Self-Balancing (Tự cân bằng): B-trees đảm bảo rằng ‘chiều cao’ của cây luôn được cân bằng ngay cả khi chèn hoặc xóa dữ liệu. Điều này đảm bảo độ phức tạp thời gian
logarithmiccho các thao tác chèn, xóa và tìm kiếm. - Ordered (Được sắp xếp): B-trees giữ dữ liệu được sắp xếp, giúp các truy vấn phạm vi (“tìm tất cả đơn hàng giữa ngày X và Y”) và các phép so sánh bất đẳng thức (inequality) rất nhanh.
- Disk-Friendly (Thân thiện với đĩa): B-trees được thiết kế để hoạt động tốt với bộ nhớ lưu trữ dựa trên đĩa. Một nút đơn lẻ của B-tree thường tương ứng với một khối đĩa (disk block), giúp giảm thiểu các thao tác truy cập đĩa.
Nhiều cơ sở dữ liệu sử dụng một biến thể B-tree hơi khác một chút gọi là B+ tree. Trong B+ tree, tất cả các giá trị dữ liệu chỉ được lưu trữ ở các nút lá, điều này có thể cải thiện hiệu suất hơn nữa cho một số trường hợp sử dụng nhất định như truy vấn phạm vi.
Hash Tables
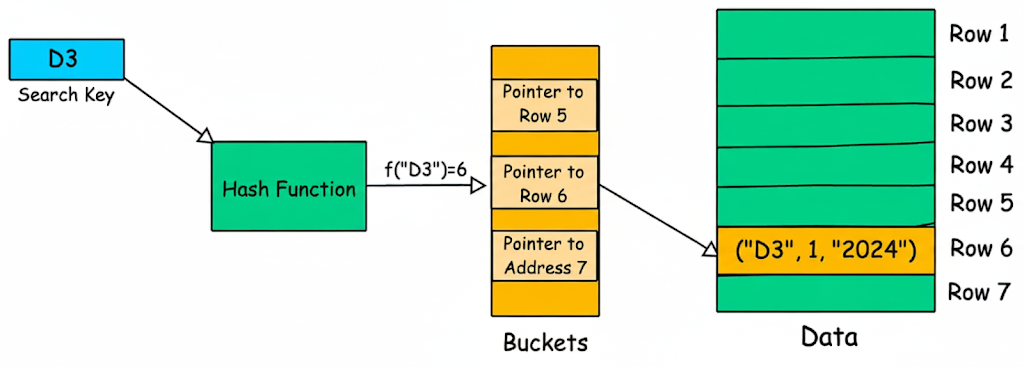
Hash tables được sử dụng cho hash indexes, vốn dựa trên một hàm băm (hash function). Một hash table bao gồm một mảng các bucket, mỗi bucket chứa địa chỉ của các hàng trong dữ liệu. Hash indexes sử dụng một hàm băm để ánh xạ các khóa đến bucket tương ứng trong bảng băm, cho phép các thao tác tra cứu trong thời gian không đổi (constant-time). Hash indexes cung cấp khả năng tra cứu bằng nhau (equality lookups) nhanh chóng, vì hàm băm xác định chính xác vị trí của dữ liệu dựa trên khóa. Tuy nhiên, hash indexes không hỗ trợ hiệu quả các truy vấn phạm vi (range queries) hoặc sắp xếp.
Bitmaps
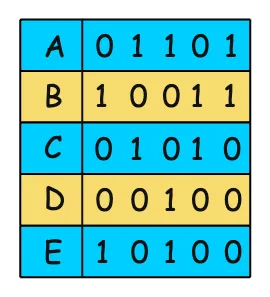
Mỗi bit trong bitmap tương ứng với một hàng, và giá trị của bit cho biết liệu giá trị khóa có tồn tại trong hàng đó hay không. Bitmap indexes sử dụng một bitmap (một mảng nhị phân) để biểu thị sự hiện diện hoặc vắng mặt của một giá trị khóa cụ thể trong mỗi hàng của bảng. Bitmap indexes rất phù hợp cho các cột có cardinality thấp (số lượng nhỏ các giá trị khác biệt) và để thực hiện các truy vấn phức tạp liên quan đến nhiều điều kiện. Các phép toán bitmap như AND, OR và NOT được thực hiện hiệu quả bằng các phép toán bitwise, khiến bitmap indexes phù hợp cho các truy vấn phân tích (analytical queries) liên quan đến nhiều cột.
6. Cách Sử Dụng Database Indexes Một Cách Thông Minh?
Để tận dụng tối đa database indexes, hãy cân nhắc các thực hành tốt nhất sau:
- Identify Query Patterns (Xác định Mẫu Truy vấn): Phân tích các truy vấn thường xuyên và quan trọng nhất được thực thi trên cơ sở dữ liệu của bạn để xác định các cột cần index và loại index cần sử dụng.
- Index Frequently Used Columns (Index các Cột Thường Được Sử Dụng): Cân nhắc index các cột thường được sử dụng trong các mệnh đề WHERE, JOIN và ORDER BY.
- Index Selective Columns (Index các Cột Có Tính Chọn Lọc Cao): Indexes hiệu quả nhất trên các cột có sự phân bố tốt của các giá trị dữ liệu (cardinality cao). Việc index một cột
gendercó thể ít hiệu quả hơn so với một cột cócustomer_idduy nhất. - Use Appropriate Index Types (Sử dụng Loại Index Phù Hợp): Chọn loại index phù hợp cho dữ liệu và truy vấn của bạn.
- Consider Composite Indexes (Cân nhắc Composite Indexes): Đối với các truy vấn liên quan đến nhiều cột, hãy cân nhắc tạo composite indexes bao gồm tất cả các cột liên quan. Điều này làm giảm nhu cầu sử dụng nhiều indexes đơn cột và cải thiện hiệu suất truy vấn.
- Monitor Index Performance (Giám sát Hiệu suất Index): Thường xuyên giám sát hiệu suất index, loại bỏ các index không được sử dụng và điều chỉnh chiến lược index của bạn khi khối lượng công việc của cơ sở dữ liệu thay đổi.
- Avoid Over-Indexing (Tránh Over-Indexing): Tránh tạo quá nhiều indexes, vì điều này có thể dẫn đến yêu cầu lưu trữ tăng lên và hiệu suất ghi chậm hơn.
- Indexes chiếm thêm không gian đĩa vì chúng là các cấu trúc dữ liệu bổ sung cần được lưu trữ cùng với các bảng của bạn.
- Mỗi khi bạn chèn, cập nhật hoặc xóa dữ liệu trong một bảng có index, index cũng cần được cập nhật. Điều này có thể làm chậm nhẹ các thao tác ghi.
Tóm lại, indexes là một công cụ mạnh mẽ để tối ưu hóa hiệu suất truy vấn cơ sở dữ liệu. Nhưng hãy nhớ chọn đúng cột và loại index, giám sát hiệu suất và tránh over-indexing để tận dụng tối đa chúng.