Việc quản lý hiệu quả các database connection là yếu tố then chốt đối với bất kỳ ứng dụng nào xử lý nhiều request. Nếu không quản lý connection đúng cách, ứng dụng của bạn sẽ nhanh chóng trở nên chậm chạp, không đáng tin cậy và tốn kém để duy trì. Database connection pooling cung cấp một cách thông minh hơn để xử lý các kết nối cơ sở dữ liệu.
Tuy nhiên, connection pooling không phải lúc nào cũng lý tưởng, đặc biệt là trong các kiến trúc serverless. Hãy cùng khám phá cơ chế hoạt động của connection pooling, hiểu rõ tầm quan trọng của nó, thảo luận về những trường hợp nó có thể không phù hợp, và tìm hiểu cách các giải pháp serverless hiện đại đang định nghĩa lại việc quản lý kết nối.
Cuộc sống không có connection pooling
Hãy tưởng tượng bạn đang xây dựng một nền tảng thương mại điện tử mới, giúp các doanh nghiệp vừa và nhỏ tạo và quản lý cửa hàng trực tuyến của họ. Nền tảng này cung cấp các tính năng như danh sách sản phẩm, quản lý kho hàng, xử lý đơn hàng và phân tích khách hàng. Ban đầu, trọng tâm là cung cấp các chức năng cơ bản như quản lý sản phẩm và quy trình thanh toán.
Bạn bắt đầu với một kiến trúc đơn giản. Backend được viết bằng Node.js và sử dụng cơ sở dữ liệu PostgreSQL. Phiên bản ngây thơ của mã truy cập cơ sở dữ liệu của bạn có thể trông như sau:

Mỗi HTTP request đều mở một database connection mới. Cách này có thể hoạt động tốt trong môi trường phát triển cục bộ hoặc triển khai nhỏ, nhưng hệ thống nhanh chóng gặp vấn đề khi lượng người dùng tăng lên. Người dùng bắt đầu phàn nàn về thời gian tải chậm, và máy chủ cơ sở dữ liệu của bạn bị quá tải do quá nhiều kết nối đang mở.
Tại sao điều đó lại trở thành vấn đề?
Việc mở một database connection mới cho mỗi request bao gồm một quy trình tốn thời gian, liên quan đến xác thực, thiết lập mạng và khởi tạo phiên làm việc. Điều này làm tăng độ trễ đáng kể, đặc biệt là trong các ứng dụng có lưu lượng truy cập cao. Cơ sở dữ liệu của bạn có một giới hạn hữu hạn về số lượng kết nối đồng thời mà nó có thể xử lý. Nếu không có pooling, bạn có nguy cơ làm quá tải cơ sở dữ liệu, dẫn đến cạn kiệt tài nguyên và thậm chí ngừng hoạt động.
Connection Pooling là gì?
Database connection pooling là một kỹ thuật cho phép các ứng dụng quản lý database connection một cách hiệu quả hơn bằng cách tái sử dụng một tập hợp các kết nối đã được thiết lập. Thay vì tạo một kết nối mới cho mỗi yêu cầu cơ sở dữ liệu, ứng dụng duy trì một pool các kết nối mở có thể được tái sử dụng, giúp giảm đáng kể thời gian và tài nguyên cần thiết để thiết lập kết nối lặp đi lặp lại.
Connection Pooling Hoạt Động Như Thế Nào
Dưới đây là cách phân tích hoạt động của connection pooling trong môi trường kỹ thuật:
- Connection Initialization: Khi ứng dụng khởi động, nó khởi tạo một số lượng cố định các database connection và lưu trữ chúng trong một pool.
- Request Handling: Bất cứ khi nào một request cần tương tác với cơ sở dữ liệu, ứng dụng sẽ mượn một connection hiện có từ pool thay vì mở một cái mới.
- Connection Reuse: Sau khi thực thi truy vấn, connection được trả lại vào pool, làm cho nó sẵn sàng cho các request trong tương lai.
- Dynamic Pool Management: Pool có thể thay đổi kích thước động, tạo thêm kết nối nếu nhu cầu vượt quá giới hạn đã định trước và giảm bớt các kết nối không hoạt động để tiết kiệm tài nguyên.
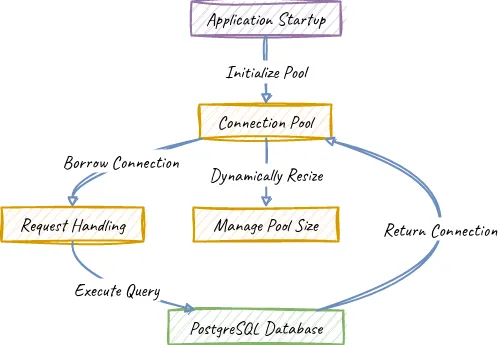
Triển Khai Connection Pooling
Mỗi môi trường phát triển trưởng thành đều có sẵn connection pooling tích hợp. Ví dụ, cho PostgreSQL:
- Java có HikariCP,
- .NET có Npgsql connection pool,
- Python có SQLAlchemy connection pool,
- Go có pgxpool cho PostgreSQL,
- Node.js có pg.Pool,
- v.v.
Đây là một đoạn mã đơn giản, nhưng thay vì tạo một kết nối mới trên mỗi request, chúng ta đang yêu cầu connection pool “cho mượn” một kết nối.
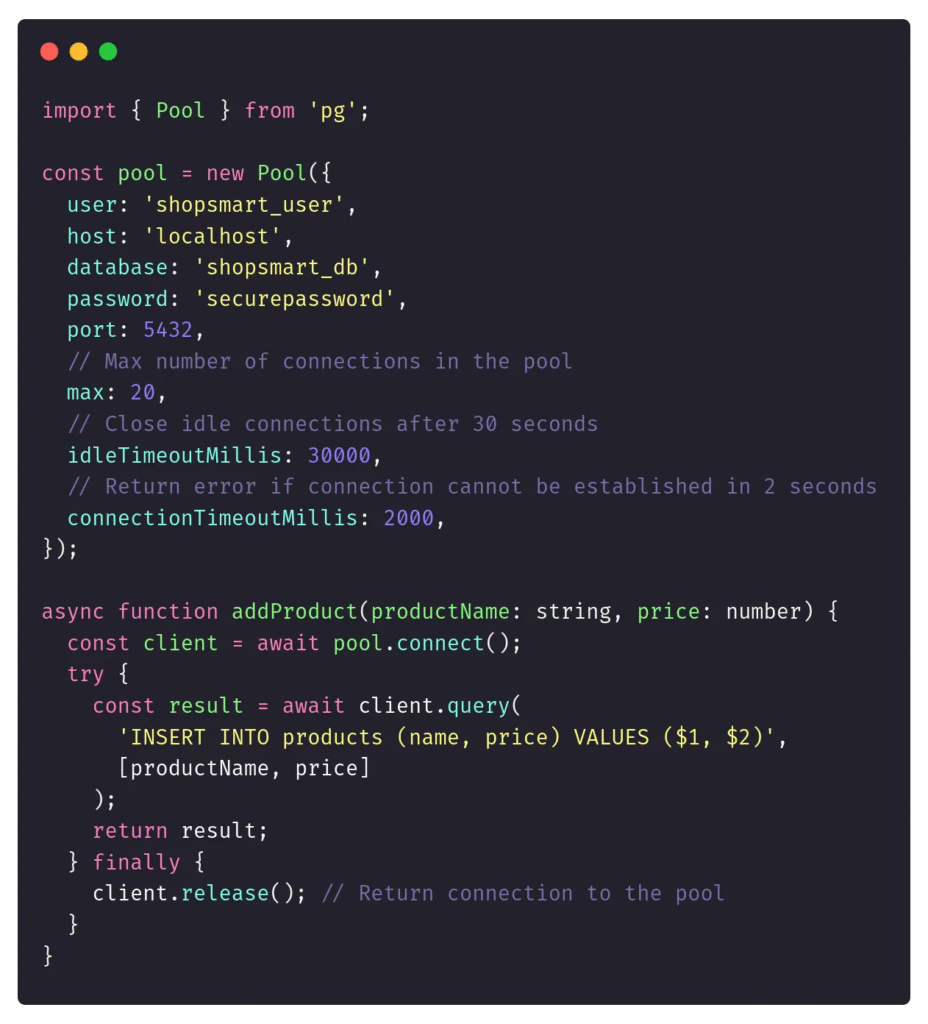
Hãy tưởng tượng một hệ thống thương mại điện tử của chúng ta đang triển khai chương trình khuyến mãi vào Black Friday và nó có thể nhận hàng nghìn request mỗi giây, mỗi request đều yêu cầu dữ liệu từ một cơ sở dữ liệu trung tâm. Nếu không có connection pooling, chi phí phát sinh do việc mở và đóng kết nối cho mỗi truy vấn sẽ khiến hiệu suất bị tê liệt. Với pooling, bảng điều khiển cung cấp thông tin chi tiết theo thời gian thực mà không bị chậm trễ.
Cơ sở dữ liệu có một giới hạn hữu hạn về số lượng kết nối đồng thời mà nó có thể xử lý. Nếu không có pooling, bạn có nguy cơ làm quá tải cơ sở dữ liệu với quá nhiều kết nối, dẫn đến cạn kiệt tài nguyên và ngừng hoạt động tiềm ẩn.
Trong các ứng dụng mà độ đồng thời cao được dự kiến, chẳng hạn như nền tảng thương mại điện tử, connection pooling giúp quản lý số lượng kết nối đang hoạt động một cách hiệu quả. Nó đảm bảo rằng cơ sở dữ liệu không bị quá tải bởi số lượng client. Connection pool giảm tải cho cơ sở dữ liệu bằng cách duy trì các kết nối được chia sẻ giữa nhiều client, tránh tải không cần thiết lên cơ sở hạ tầng cơ sở dữ liệu của bạn.
Khi ứng dụng của bạn mở rộng, số lượng database request mà nó phải xử lý cũng tăng lên. Connection pooling cho phép các ứng dụng quản lý hiệu quả một khối lượng lớn các kết nối đồng thời, cung cấp một cách đáng tin cậy để xử lý các đợt tăng lưu lượng truy cập mà không làm giảm hiệu suất hoặc quá tải cơ sở dữ liệu.
Tất cả những điều đó nghe thật tuyệt vời, nhưng chúng ta không thể chỉ có toàn điều tốt. Vì vậy, hãy cùng thảo luận…
Thách Thức và Những Điều Cần Cân Nhắc
Mặc dù connection pooling mang lại nhiều lợi ích, nhưng nó cũng đi kèm với những thách thức riêng mà bạn phải giải quyết để đảm bảo hiệu suất tối ưu. Như bạn đã thấy trong đoạn mã, connection pool cung cấp cho bạn nhiều cài đặt cấu hình.
Mỗi triển khai có thể có cài đặt riêng, nhưng quan trọng nhất là:
- pool size
- connection timeout.
Việc chọn kích thước pool phù hợp là rất quan trọng để tránh các nút cổ chai hoặc cạn kiệt tài nguyên. Quá ít kết nối có thể dẫn đến các request bị xếp hàng đợi, trong khi quá nhiều có thể làm quá tải tài nguyên cơ sở dữ liệu, làm giảm hiệu suất.
Không thể nói kích thước nào là tốt nhất cho ứng dụng của bạn. Đó là điều gì đó cần bao gồm các đặc điểm cụ thể của:
- đặc điểm workload,
- dung lượng cơ sở dữ liệu,
- yêu cầu ứng dụng.
Chúng ta nên phân tích workload của ứng dụng để xác định số lượng kết nối tối ưu, xem xét các mô hình sử dụng trong giờ cao điểm và giờ thấp điểm.
Sau đó, hãy xem xét dung lượng cơ sở dữ liệu và hiểu rõ giới hạn của nó. Điều này rất quan trọng để ngăn chặn việc quá tải nó với quá nhiều kết nối.
“Quá nhiều” nghĩa là gì? Nó có thể có nghĩa khác nhau đối với từng ứng dụng. Thông tin cơ bản đến từ việc xem xét số lượng người dùng và request đồng thời mà ứng dụng của chúng ta cần hỗ trợ. Nhưng tất nhiên, chúng ta nên hiểu trường hợp sử dụng kinh doanh của mình để thiết lập các chỉ số dựa trên nhu cầu thực tế.
Việc đạt được sự cân bằng phù hợp giữa hiệu suất và việc sử dụng tài nguyên đòi hỏi phải tinh chỉnh cẩn thận các cài đặt pool. Trong khi một pool lớn hơn có thể xử lý nhiều request hơn, thì nó cũng tiêu thụ nhiều tài nguyên hơn. Ngược lại, một pool nhỏ hơn có thể dẫn đến tranh chấp và độ trễ.
Chúng ta có thể thử triển khai các thuật toán thay đổi kích thước pool động, điều chỉnh kích thước pool dựa trên nhu cầu hiện tại và khả năng tài nguyên. Tất nhiên, điều đó rất phức tạp, và chúng ta nên bắt đầu bằng cách liên tục giám sát và tinh chỉnh các cài đặt khi hệ thống của chúng ta phát triển.
Connection Leaks
Connection leaks là một trong những vấn đề phổ biến nhất. Chúng xảy ra khi các kết nối không được trả lại đúng cách vào pool, dẫn đến sự cạn kiệt dần dần các kết nối có sẵn và cuối cùng là sự cố ứng dụng. Điều này thường xảy ra khi nhà phát triển quên đóng một kết nối sau khi sử dụng.
Việc sử dụng khối try/finally có thể giúp giải quyết vấn đề này. Chúng ta đã làm điều đó trong đoạn mã ở trên. Điều đó đảm bảo các kết nối luôn được trả lại vào pool, ngay cả khi một ngoại lệ xảy ra.
Tất nhiên, chúng ta nên giảm thiểu số lượng thứ mà các nhà phát triển cần phải nhớ. Đó là lý do tại sao việc đưa quá trình dọn dẹp này vào một số wrapper chung là đáng giá, giúp giảm khả năng bị sử dụng sai. Helper được cập nhật của chúng ta có thể trông như sau:
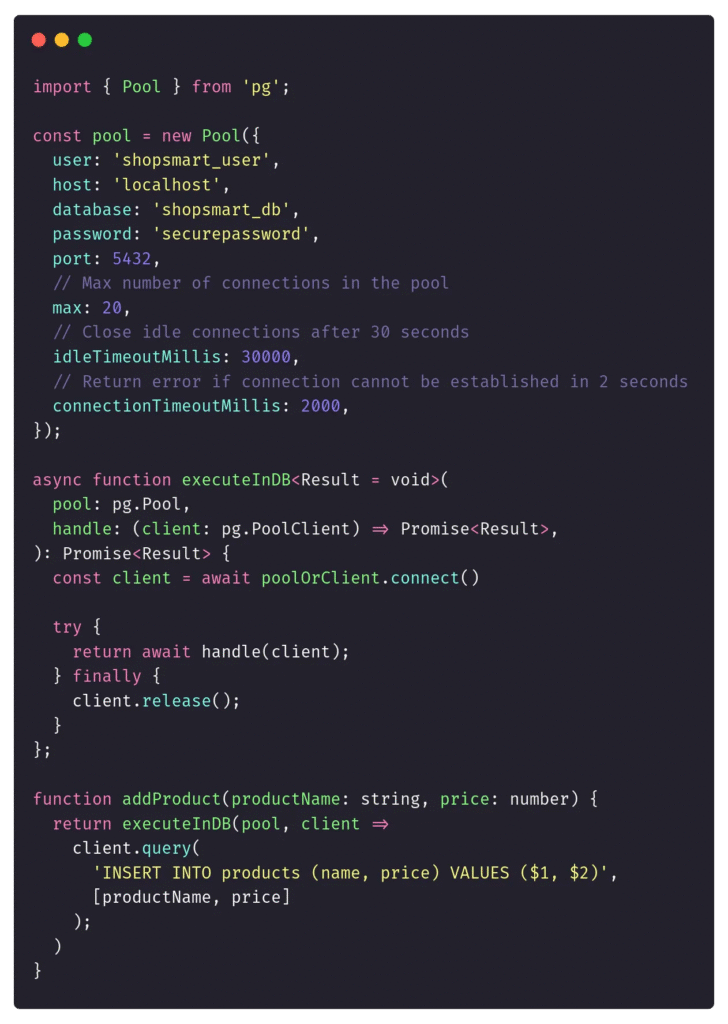
Nhưng ngay cả với điều đó, chúng ta vẫn nên liên tục giám sát việc sử dụng connection của mình để xác định xem chúng ta có bị rò rỉ kết nối tiềm ẩn hay không.
Các Cân Nhắc Về Bảo Mật
Khi chúng ta chia sẻ kết nối giữa nhiều thao tác, chúng ta cũng chia sẻ các thông tin xác thực mà chúng ta kết nối. Điều này có thể khiến việc sử dụng một số tính năng như Row-based security trở nên khó khăn hơn. Chúng ta sẽ luôn kết nối với cơ sở dữ liệu với cùng một người dùng.
Điều này có thể thúc đẩy bạn triển khai Access Control ở tầng ứng dụng. Một tùy chọn khác là có nhiều connection pool. Mỗi connection pool sẽ liên quan đến các Permission Groups/Roles cụ thể (ví dụ: các connection pool khác nhau cho admin và người dùng thông thường).
Việc duy trì một pool lớn các kết nối mở có thể gây rủi ro trong các môi trường mà bảo mật là mối quan tâm quan trọng. Nếu một kết nối trong pool bị xâm phạm, nó có thể dẫn đến truy cập trái phép vào cơ sở dữ liệu.
Hãy đảm bảo các biện pháp bảo mật thích hợp, chẳng hạn như mã hóa và kiểm soát truy cập, được áp dụng khi sử dụng connection pooling. Nếu không thể đảm bảo an toàn, bạn có thể cân nhắc các giải pháp thay thế cung cấp quyền kiểm soát chặt chẽ hơn đối với quyền truy cập kết nối.
Connection Pools, Microservices và Định luật Conway
Ngày nay, Định luật Conway luôn phải được nhắc đến, phải không? Nhưng tại sao lại ở đây?
Việc sử dụng một thư viện connection pool như pg.Pool trong Node.js là một bước đầu tiên tốt để triển khai connection pooling cho nhiều ứng dụng. Nó đơn giản, dễ thiết lập và cung cấp một mức độ pooling cơ bản ngay lập tức. Bạn đã thấy rằng việc tái cấu trúc từ thiết lập không có pooling nên khá dễ dàng đối với các ứng dụng quy mô vừa và nhỏ.
Tuy nhiên, nó giả định rằng bạn có một pool cho mỗi lần triển khai. Điều này hoạt động rất tốt cho các hệ thống đơn khối hoặc không quá phân tán, nhưng…
Chuyện gì xảy ra nếu bạn có nhiều instance của cùng một dịch vụ và thực hiện load balancing?
Chuyện gì xảy ra nếu bạn có microservices với hàng chục dịch vụ được triển khai?
Chuyện gì xảy ra nếu bạn không chỉ có các ứng dụng Node.js mà còn viết bằng các stack khác (ví dụ: Java, C#, Python, v.v.)?
Điều này có thể dẫn đến việc lặp lại thiết lập connection pool trong mỗi môi trường phát triển, điều này có thể gây đau đầu trong việc bảo trì.
Ngoài ra, nếu tất cả các ứng dụng đó sử dụng cùng một cơ sở dữ liệu (ví dụ: chia sẻ theo schema cơ sở dữ liệu), chúng sẽ không sử dụng cùng một pool, điều này có thể lại dẫn đến tình trạng cạn kiệt pool.
Đối với những tình huống này, bạn có thể cân nhắc sử dụng một dịch vụ chuyên dụng để pooling. Nó sẽ hoạt động như một proxy giữa ứng dụng của chúng ta và cơ sở dữ liệu. Các ví dụ có thể như sau:
- MySQL: ProxySQL hoặc MySQL Router
- MSSQL: odbc-bcp
- Oracle: odpi-pool, MaxScale
- PostgreSQL: pgBouncer
Connection Pool Proxy Service
pgBouncer là một trình pool kết nối chuyên biệt cho PostgreSQL, cung cấp các tính năng nâng cao vượt ra ngoài những gì có sẵn trong các thư viện cơ bản. Nó được biết đến với hiệu suất cao và lượng bộ nhớ thấp, làm cho nó phù hợp với các ứng dụng đòi hỏi khắt khe. pgBouncer hoạt động như một lớp trung gian giữa ứng dụng của bạn và máy chủ PostgreSQL. Nó duy trì một pool các kết nối đến máy chủ và multiplex các kết nối client, quản lý tài nguyên một cách hiệu quả.
Để cấu hình nó, chúng ta cần cài đặt nó trên máy chủ của mình:
sudo apt-get install pgbouncerThiết lập cấu hình và tham chiếu đến cơ sở dữ liệu PostgreSQL của chúng ta trong pgbouncer.ini:
[databases]
mydb = host=localhost port=5432 dbname=mydb
[pgbouncer]
listen_addr = 127.0.0.1
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
pool_mode = transaction
max_client_conn = 100
default_pool_size = 20Sau khi có cấu hình, chúng ta có thể khởi động dịch vụ:
sudo service pgbouncer startBây giờ, chúng ta cần sửa đổi ứng dụng của mình. Chúng ta không thể sử dụng application level pool nữa. Nếu chúng ta làm vậy, chúng sẽ xung đột với nhau. Nếu chúng ta đang sử dụng connection pool proxy, chúng ta phải tạo một client mỗi lần và để proxy quản lý các kết nối bên trong. Đoạn mã được cập nhật sẽ trông như thế này:
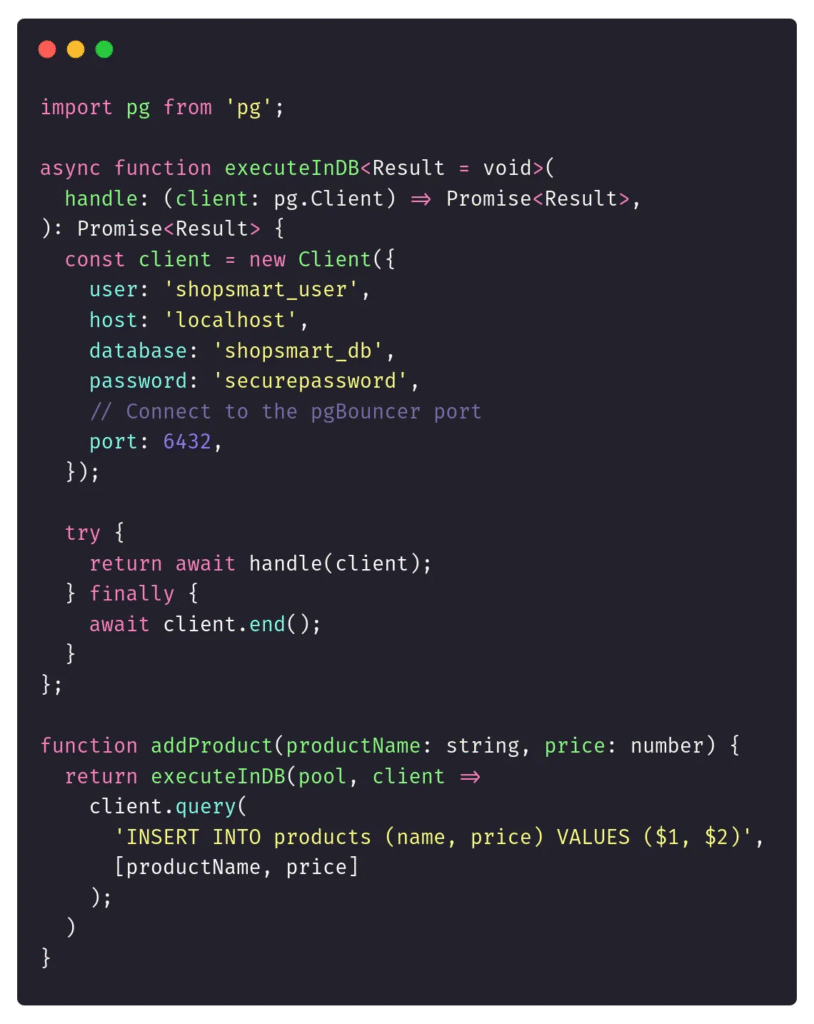
Tương tự cho các dịch vụ khác. Mỗi dịch vụ có thể chỉ sử dụng kết nối gốc mà không cần biết đến pooling.
Một dịch vụ proxy như pgBouncer có thể giúp tăng tốc và xử lý nhiều giao dịch hơn mà không gây áp lực lên ứng dụng. Nó cũng có thể mở rộng độc lập với ứng dụng. Vì nó được thiết kế để xử lý connection pool một cách thuần túy, nó có thể được tối ưu hóa tốt hơn và phù hợp hơn với các môi trường bị hạn chế tài nguyên.
Như mọi khi, những ưu điểm có thể dễ dàng trở thành nhược điểm tùy thuộc vào góc nhìn. Chúng yêu cầu cấu hình và bảo trì bổ sung so với các giải pháp dựa trên thư viện. Mặc dù hiệu quả, chúng thiếu một số tính năng nâng cao như query rewriting hoặc các tối ưu hóa ở cấp độ giao thức được tìm thấy trong các giải pháp khác.
Các Best Practices Triển Khai Connection Pooling
Hãy cùng điểm lại những bài học và cố gắng đưa ra một bản tóm tắt về những gì việc triển khai connection pooling một cách hiệu quả đòi hỏi phải tuân thủ các thực hành tốt nhất để đảm bảo hiệu suất tối ưu và quản lý tài nguyên. Dưới đây là một số khuyến nghị:
- Bạn có thể bắt đầu đơn giản bằng cách sử dụng các thư viện connection pooling đáng tin cậy. Chọn một thư viện hoặc framework connection pooling phù hợp với nhu cầu của ứng dụng bạn. Những thư viện này cung cấp hỗ trợ tích hợp cho connection pooling và cung cấp nhiều tính năng để tùy chỉnh và tối ưu hóa hành vi của pool.
- Xử lý việc giải phóng connection một cách duyên dáng để ngăn ngừa connection leaks. Đảm bảo bạn giải phóng connection (ví dụ: trong khối try/finally hoặc helper có thể tái sử dụng). Bạn cũng có thể triển khai logic thử lại để xử lý các lỗi kết nối tạm thời một cách duyên dáng. Cung cấp các cơ chế dự phòng để đảm bảo tính liên tục của dịch vụ trong trường hợp có sự cố kết nối.
- Nếu bạn đang làm việc với microservices, Kubernetes hoặc nhiều stack công nghệ, hãy cân nhắc sử dụng một dịch vụ proxy như pgBouncer để thống nhất load balancing.
- Nếu bạn đang làm việc với Serverless, hãy kiểm tra các dịch vụ được quản lý có sẵn trên nền tảng của bạn như AWS RDS Proxy, Cloudflare Hyperdrive, Supabase Supervisor. Connection pooling truyền thống có thể không phải là lựa chọn phù hợp nhất trong các môi trường serverless do bản chất không có trạng thái của các hàm serverless.
- Giám sát và tinh chỉnh cài đặt pool thường xuyên. Điều này rất cần thiết để duy trì hiệu suất tối ưu. Theo dõi các chỉ số như việc sử dụng connection, thời gian chờ và kích thước pool để xác định các vấn đề tiềm ẩn. Liên tục đánh giá hệ thống của bạn khi nó phát triển.
Database connection pooling là điều thiết yếu để tối ưu hóa hiệu suất và sử dụng tài nguyên trong các ứng dụng hiện đại. Bằng cách tái sử dụng các kết nối hiện có, pooling giúp giảm độ trễ, cải thiện khả năng mở rộng và đảm bảo sử dụng tài nguyên hiệu quả. Tuy nhiên, nó cũng đòi hỏi cấu hình và giám sát cẩn thận để tránh các cạm bẫy như connection leaks và cạn kiệt tài nguyên.
Bằng cách triển khai các thực hành tốt nhất và tận dụng các chiến lược connection pooling đáng tin cậy, bạn có thể xây dựng các ứng dụng hiệu suất cao và kiên cường, có khả năng xử lý lưu lượng truy cập cao và các workload đòi hỏi khắt khe.
Trong phát triển phần mềm, việc thành thạo connection pooling giống như có một động cơ được bôi trơn tốt—nó giúp mọi thứ vận hành trơn tru và hiệu quả. Vì vậy, hãy dành thời gian để hiểu và triển khai connection pooling trong các dự án của bạn.